Markdown comme condition d'une norme de l'écriture numérique
Si le standard du web est le HTML, comment Markdown peut-il être la norme de l’écriture numérique ? Inventé par John Gruber au début des années 2000, Markdown est un langage sémantique qui permet d’écrire du HTML — Hyper Text Markup Language — avec un système de balisage bien plus léger. D’abord plébiscité par les développeurs pour rédiger leur documentation, cette syntaxe est désormais de plus en plus employée, notamment dans des applications numériques qui cherchent à se passer d’interfaces WYSIWYG — What You See Is What You Get : ce que l’on voit est ce que l’on obtient, fonctionnement des traitements de texte classiques. Pensé pour distinguer la structure sémantique et la mise en forme d’un document, et être très facilement transformable en HTML, Markdown devient le pivot de l’écriture numérique, rendant les fichiers sources tout autant lisibles par des humains, interopérables pour les machines ou résilients. En plus de Markdown, d’autres langages sémantiques comme AsciiDoc semblent s’imposer face aux interfaces WYSIWYG qui n’ont pas résolu le problème de l’interaction homme - texte structuré, et que LaTeX a limité à des usages universitaires.
Ce texte a été écrit en septembre 2017 pour le sixième numéro de la revue Réel-Virtuel : enjeux du numérique, numéro dont la thématique est “Les normes du numérique”, l’article original est disponible en ligne :
http://www.reel-virtuel.com/numeros/numero6/sentinelles/markdown-condition-ecriture-numerique
Introduction
Dans un univers numérique largement dominé par le texte, la lecture numérique dispose d’un standard structurant les contenus, permettant un accès multi-supports, ouvrant la perspective de l’archivage, etc. Il semble que nous puissions toutefois constater l’absence d’un processus normalisé d’écriture numérique. Le format HTML est désormais à la base de nos pratiques de lecture, que ce soit sur le Web, par mail, avec les livres numériques, ou via des dispositifs aussi différents qu’un ordinateur, un téléphone, une tablette ou une liseuse. Des tentatives telles que les traitements de texte ou le mode WYSIWYG1 sont-elles des solutions adéquates à la question de la structuration sémantique et pour la facilité de compréhension et d’usage de celle-ci ? Nous proposons plutôt de rechercher du côté des langages de balisage léger, offrant la possibilité de distinguer la structure sémantique et la mise en forme d’un document, et étant très facilement transformable en HTML.
Une norme de l’écriture numérique ? Considérons la norme comme une série de règles construites au fil du temps, établissant une référence commune et aboutissant à la constitution de standards. La question d’une norme ne concerne alors pas tant un format qu’un processus, ce dernier étant permis par un langage sémantique compréhensible par les humains et les machines.
1. Le langage HTML comme standard de la lecture numérique
Si le Web est d’abord une invention visant à lier des documents structurés, et que le numérique regroupe principalement le Web et ses usages divers, alors le langage HTML, qui est le standard du web, est à la base du document numérique, aux côtés d’autres formats.
1.1. Un Web de documents
Nous faisons le constat que le numérique regroupe le Web – en tant qu’ensemble de pages web reliées entre elles – et ses différentes formes – sites web, applications basées sur ce media/médium, mail, livre numérique, etc. Partons ainsi d’une considération forte : le document numérique est avant tout un document web. Nous écartons volontairement le format PDF, même s’il représente une quantité importante des documents numériques, et même si son hégémonie en terme d’usage est une hégémonie par défaut, faute de mieux. Le format PDF est le reflet d’usages encore contraints par l’univers imprimé : il n’est qu’un format portable, comme son nom l’indique2, avant tout destiné à l’impression, qui conserve une structuration formelle sans conserver de structuration sémantique. Un document numérique est un contenu dont la structure est distincte de la mise en forme, sa structure sémantique peut être simple mais elle est néanmoins puissante. La question qui nous porte ici n’est pas tant celle du format que celle des usages3.
À l’origine du Web est la volonté de lier des documents entre eux, il s’agit de la première intention de Tim Berners-Lee, son inventeur, et de son équipe : penser un système permettant de créer et de gérer des documentations interconnectées. Si le Web devient aujourd’hui applicatif, il est déterminant de garder à l’esprit que son modèle et son infrastructure ont été conçus pour lire des documents. Le Web est constitué de deux éléments interdépendants : HTTP et HTML. D’une part un protocole de communication, et d’autre part un langage de balisage, un standard pour structurer l’information. Le lien hypertexte, la quintessence du Web, associe très intimement ce protocole et ce standard, car le lien hypertexte a autant besoin d’être identifié via une sémantique particulière que d’une connexion pour passer d’une page web à une autre.
La révolution du Web repose sur une idée somme toute assez simple, anticipée par plusieurs intellectuels bien avant sa réalisation comme Paul Otlet4 ou Vannevar Bush au début du vingtième siècle : lier des documents structurés. Permise par un système clair et concis, cette technologie est toutefois sophistiquée dans sa mise en place : si le standard HTML est relativement simple à appréhender, le protocole HTTP est plus complexe. Quand bien même les premières recherches et réalisations en matière de document numérique précèdent le Web et que le format PDF est encore très utilisé, le format HTML est le standard le plus largement répandu, et il définit à lui seul les trois dimensions du document distinguées par Roger T. Pédauque : le document comme forme, comme signe et comme médium5.
1.2. Une brève histoire d’HTML
Nous concentrons ici notre réflexion sur le format HTML, et nous nous détachons quelque peu du Web dans sa globalité. L’HyperText Markup Language est un langage de balisage qui a été créé pour structurer les contenus à la fois sémantiquement et logiquement. La structuration sémantique consiste en la qualification d’une information, par exemple un titre de niveau 1, ou encore un passage en emphase. La structure est signifiée indépendamment du contenu. À partir de cela, une mise en forme peut être attribuée au contenu, par exemple un corps de texte de taille importante pour le titre de niveau 1, ou de l’italique pour le passage en emphase. La structuration logique concerne l’organisation globale du document, notamment l’en-tête – head – qui précède le corps – body – ou encore le paragraphe qui est lui-même compris dans une section – une section étant un texte inclut dans un texte. Nous pouvons également prendre l’exemple de l’enchaînement des niveaux de titre : un niveau quatre suivra un niveau trois qui lui-même suivra un niveau deux, et ainsi de suite.
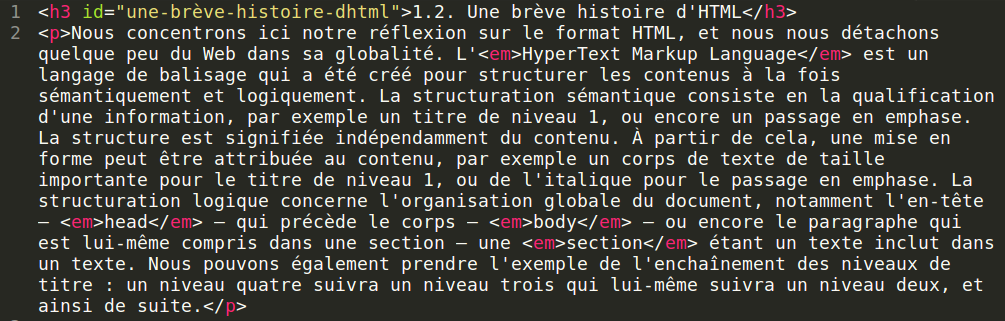 Figure 1 : exemple d’équivalence en HTML du paragraphe ci-dessus
Figure 1 : exemple d’équivalence en HTML du paragraphe ci-dessus
Nous ne nous attarderons que brièvement sur l’histoire de l’HTML, mais nous devons noter son origine : le SGML, ou Standard Generalized Markup Language, dont le XML – Extensible Markup Language – dérive également. D’autres initiatives ont donc précédé l’HTML, souvent plus riches mais aussi bien plus savantes, elles ont permis l’existence de ce standard qui est aujourd’hui le plus utilisés. L’objectif initial de la création d’HTML est double : structurer des contenus, comme nous l’avons déjà souligné, et permettre une interopérabilité. Ce dernier point est essentiel pour comprendre le succès d’HTML. La révolution du Web est de permettre à n’importe quelle machine informatique d’accéder à des contenus et de les afficher d’une façon graphiquement similaire à une autre machine informatique. Les questions de compatibilité d’un document, dépendant du matériel, du système d’exploitation ou du logiciel de consultation sont donc résolues. Le format HTML connaît de nombreuses évolutions6, passant de HTML+ à des versions 2, 3 ou 4, effectuant un passage par le XHTML pour enfin aboutir à une version en constante évolution, aujourd’hui identifié par l’HTML57. Les détails de ces évolutions, tant du point de vue technique que technologique, mériteraient un plus long développement illustré d’exemples et d’anecdotes, mais ce n’est pas l’objet du présent article.
SGML est désormais très peu utilisé, et à une moindre échelle XML tend à laisser la place à HTML5. Pourquoi HTML s’en sort mieux que son parent XML ? Probablement parce qu’un fichier XML dépend d’une DTD, une définition de type de document qui explicite la grammaire utilisée. XML a une faculté de personnalisation, le créateur d’un fichier peut en effet définir de nouveaux éléments pour des usages particuliers. Sans sa DTD un fichier XML a de grande chance d’être illisible. Contrairement à cela, HTML contient un nombre arrêté d’éléments définis dans un standard, sans customisation possible. XML est puissant mais difficile à lire – pour un humain ou une machine –, HTML est contraint mais standardisé et interopérable, et presque lisible par un humain. HTML porte le pouvoir de la standardisation : les navigateurs web peuvent définir une façon précise et commune d’afficher telle information structurée. Nous n’abordons pas les questions de mise en forme via l’usage des feuilles de style CSS, mais il s’agit d’un autre standard associé à HTML : CSS est la description d’une mise en page, les détails de la mise en forme étant attribués via les informations de structuration indiquées en HTML. Nous pouvons reprendre l’exemple ci-dessus : un passage est qualifié comme étant un titre de niveau 1 dans un fichier HTML, la feuille CSS se charge de définir graphiquement l’apparence d’un titre de niveau 1 (type de police de caractères, taille, couleur, espacements, etc.).
1.3. HTML partout
Un document numérique est un document structuré, c’est-à-dire que chaque information est qualifiée – niveau de titre, paragraphe, emphase par exemple, comme expliqué plus haut. D’une certaine façon un document au format PDF n’est pas forcément un document numérique, le format PDF n’assurant pas toujours une structure. Au mieux le PDF est une dématérialisation, une image numérique figée d’un document physique – et le moyen le plus simple, nous devons le reconnaître, de conserver l’apparence d’un document. Le format HTML est à la base de la grande majorité de nos lectures numériques, depuis plus de vingt ans il en est devenu le standard, en tant qu’il assure cette fonction de structuration de l’information, qu’il distingue les contenus et leur mise en forme, et qu’il est interopérable et pérenne8. Sans que nous en soyons conscients lors de nos usages9, HTML est prédominant dans nos pratiques de lecture numérique : web, livre numérique, applications, etc., que ce soit sur smartphone, ordinateur, tablette, etc.
Quelques implications résultent de cela : la mise en forme d’une page web peut être modifiée – d’où le succès du mode zen des navigateurs ou de certaines applications de read it later10 qui reformatent une page web –, chaque document HTML est compréhensible par une machine, et donc ouvre des perspectives en terme d’accessibilité – une information structurée peut être lue par une synthèse vocale ou rendue dans une plage braille pour des utilisateurs ayant des déficiences visuelles par exemple. D’un point de vue technique cela signifie qu’un contenu ne doit pas nécessairement être modifié pour changer sa mise en forme11, c’est un gain de temps et d’énergie très important. Enfin, la mise en forme associée à un document HTML peut s’adapter au dispositif qui l’affiche, c’est sous le nom de responsive web design – design web responsif – que cette faculté incroyable a été démocratisée lors de l’expansion du smartphone et des tablettes : une même page web peut prendre différents aspects, et ainsi rester lisible autant sur un écran d’ordinateur, au format paysage, que sur un écran de téléphone, au format portrait. Le développement de dispositifs de lecture autre que l’ordinateur a clairement renforcé la nécessité d’un format commun, normalisé12.
 Figure 2 : exemple d’une page web qui s’adapte à la largeur de l’écran
Figure 2 : exemple d’une page web qui s’adapte à la largeur de l’écran
Si nous disposons désormais d’un standard pour la structuration des documents numériques, et donc pour l’accès et la lecture numériques, il est intéressant de souligner que ce n’est pas le cas du côté de l’écriture numérique, c’est-à-dire l’inscription de contenus et la production d’un document numérique. Écrire directement en HTML est possible mais n’est pas recommandé pour deux raisons principales : la première est le manque de lisibilité du format, bien trop bruyant pour la plupart des humains qui n’ont pas à déchiffrer un langage syntaxique riche – même si plus léger que certaines applications de XML ; la seconde est que le format évolue rapidement et sans cesse, rendant dépassé – mais pas obsolète – ce qui a été écrit hier en HTML. Dans les faits personne ou presque n’écrit en HTML. Après plusieurs décennies d’évolutions techniques et technologiques, comprenant l’informatique et le Web, nous devons reconnaître l’absence de standard pour l’écriture numérique, malgré de nombreuses tentatives. Les besoins sont pourtant bien identifiés, il s’agit de faciliter l’accès à l’écriture, d’obtenir l’interopérabilité du format, de le rendre lisible par des humains ou des programmes, de pouvoir le transposer dans d’autres formats, en un mot : normaliser.
2. L’échec des traitements de texte et des interfaces WYSIWYG
La recherche d’outils d’écriture numérique est une entreprise aussi vieille que l’informatique. Parmi ces initiatives d’inscription et de structuration du texte sous forme numérique, arrêtons-nous sur l’approche WYSIWYG, pour What You See Is What You Get, ou ce que vous voyez est ce que vous obtenez en français : elle permet de voir à la fois l’inscription d’un contenu et sa mise en forme. L’information structurée et qualifiée prend forme. Depuis les logiciels jusqu’aux applications web, les WYSIWYG ont gagné un succès d’usage, présentant dans le même temps des limites et remettant en cause le principe même d’écriture numérique.
2.1. Écrire, voir et imprimer : l’approche logiciel
Le logiciel le plus représentatif du mode WYSIWYG est le traitement de texte, et plus particulièrement celui de Microsoft : Word. Censé faciliter l’écriture numérique, celui-ci a tout d’abord été pensé pour produire des documents imprimés. Il répondait, et répond encore, à un double mouvement, la possibilité d’écrire et de produire des documents d’un côté, et de l’autre faciliter cette action pour tout un chacun. Dès l’apparition de l’informatique personnelle, la bureautique a pris une place considérable : créer des documents est devenu une nécessité, et qui plus est avec des possibilités de mise en forme évoluée, proches des logiciels de PAO13. Word répond à ces différentes contraintes avec une interface homme-machine simple d’usage composée de menus pour réaliser tout type d’action : modifier les contenus, intervenir sur la mise en forme, qualifier l’information, etc.
L’objectif du logiciel Microsoft Word – mais également d’autres logiciels comme WordPad, OpenOffice, Pages, LibreOffice Writer, etc. – est d’afficher à l’écran ce qui sera ensuite imprimé. Ce point est essentiel pour comprendre le fonctionnement d’un traitement de texte classique, et les usages qu’il occasionne. Si aujourd’hui il s’agit autant d’imprimer un support papier que de produire une version numérique figée au format PDF, le paradigme reste le même : l’action de l’utilisateur au moment de l’écriture numérique a pour objectif final un résultat graphique14. La question de la structuration sémantique n’est que secondaire. Elle permet par exemple de simplifier le processus : plutôt que de modifier tous les passages considérés comme des titres de niveau 1 pour qu’ils soient d’une taille de caractère plus grande – sélectionner un premier passage, changer la taille de la police, sélectionner un second passage, etc. –, il suffira d’attribuer la qualification de titre de niveau 1 à ces passages, puis d’appliquer une feuille de style, et enfin de modifier la feuille de style, alors la mise en forme de chaque passage sera automatiquement modifiée.
L’écriture numérique avec des traitements de texte se résume donc majoritairement à une structuration visuelle de l’information, lisible uniquement par des humains, et non par des machines comme un navigateur web ou un lecteur de livre numérique. Qu’en est-il de l’écriture numérique pour le Web, et non plus uniquement pour des documents imprimés ?
2.2. Écrire sur le web : l’ère du WYSIWYG
Après une période où les pages web doivent forcément s’écrire en HTML, à la main, ou bien sans mise en forme (en texte brut), des applications d’écriture numérique apparaissent, conçues pour rendre la mise en page et la production de sites web bien plus simple. Les premières interfaces, souvent intégrées dans les systèmes de gestion de contenu – ou CMS pour Content Management System –, s’inspirent des traitements de texte, en simplifiant leur fonctionnement : quelques options de mise en forme comme le gras ou l’italique, des niveaux de titre ou encore des listes. Le principe consiste donc à produire du code HTML à partir d’un traitement de texte minimaliste : l’utilisateur met en forme son document, et l’application se charge de traduire cela en balises HTML, en associant ensuite une feuille de style.
Les interfaces WYSIWYG ont démocratisé la création de pages et de sites web, participant à l’essor des blogs au début des années 2000. Créer un document numérique comme une page web ne nécessite plus de compétences en HTML, la barrière du code est levée. Le résultat est donc une production importante de documents numériques, et le développement d’une pratique d’écriture elle aussi numérique – d’une certaine pratique pouvons-nous ajouter, finalement assez proche de celle générée par les traitements de texte. L’objectif de ces outils WYSIWYG est de produire des contenus mis en forme, en utilisant les propriétés d’HTML et de CSS – distinguer le fond et la forme.
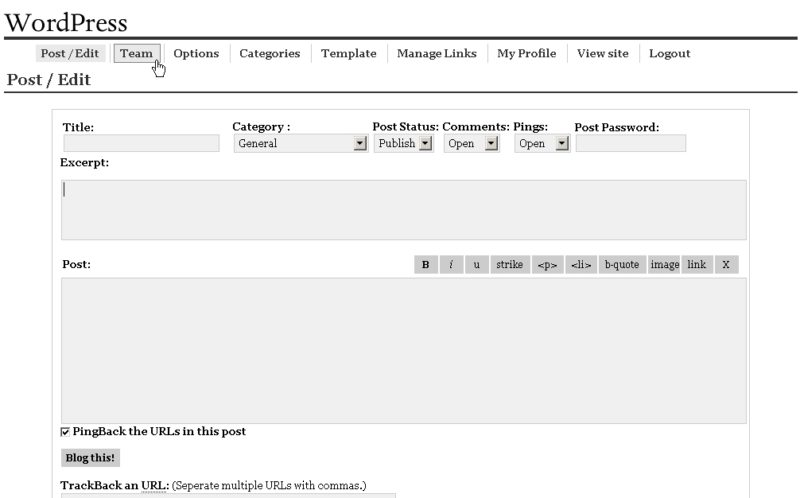 Figure 3 : exemple d’interface WYSIWYG avec une des premières versions du CMS WordPress (source)
Figure 3 : exemple d’interface WYSIWYG avec une des premières versions du CMS WordPress (source)
Le résultat est néanmoins similaire à celui des traitements de texte : l’action de l’inscription des contenus est confondue avec celle de la qualification de l’information, elle-même associée à celle de la mise en forme. Pour illustrer cette confusion entre sémantique et rendu graphique : certaines fonctions étant relativement mal présentées, certains rédacteurs vont qualifier un passage en titre 2 pour qu’il apparaisse avec telle mise en forme graphique, alors que le passage n’a pas cette propriété. Un autre élément, technique cette fois, doit être mentionné : la qualité du code HTML produit par ces outils est parfois exécrable, ajoutant des balises inutiles, rendant le code trop verbeux, ne respectant pas toujours les standards, et créant même des erreurs. L’ère des WYSIWYG est une révolution positive en terme d’usages engendrés, mais triste au regard des résultats sémantiques.
2.3. La limite des interfaces WYSIWYG
Comme nous l’avons aperçu ci-dessus, l’approche WYSIWYG présente plusieurs limites inhérentes à son principe de fonctionnement. Pensé pour l’impression, un traitement de texte crée une confusion entre la structure et la mise en forme d’un document. Par ailleurs le caractère fermé ou opaque des processus du logiciel rend sa compréhension quasiment impossible. Un texte en gras et en corps 24 ne sera pas un titre de niveau 2, à moins de qualifier ce texte sémantiquement. Conçues pour rendre la création et l’édition de contenus web plus simples, le mode WYSIWYG provoque le même amalgame entre le contenu, sa structure sémantique et sa mise en forme, et tend à générer des erreurs techniques.
Nous pouvons noter deux échecs liés au principe même du mode WYSIWYG pour le Web. Le premier est de ne pas avoir poussé le principe jusqu’au bout, assurant la même mise en page lors de l’édition et après production de la page HTML15, en effet il y a toujours un décalage plus ou moins important, notamment lié au fait que l’édition ne concerne qu’une partie du contenu d’une page, ou que la feuille de style de prévisualisation lors de l’édition n’est pas la même que celle du rendu final. Le second échec est un leurre, car le mode WYSIWYG suppose que la façon dont nous mettons en forme un document devra être similaire partout, sans accepter qu’il puisse y avoir des différences : par exemple entre deux navigateurs web, ou dans le cas du livre numérique entre deux dispositifs ou applications de lecture16, ou encore dans le temps en fonction des évolutions des standards ou des moteurs de rendu.
Si certains militent pour l’abolition du WYSIWYG17, un autre mode d’écriture numérique cherche à rétablir la problématique de la sémantique, le WYSIWYM pour What You See Is What You Mean18. Centré sur le sens plutôt que sur la forme, le mode d’édition WYSIWYM cherche ainsi à limiter la confusion entre structure et mise en forme, et supprimer la mauvaise qualité du code produit. Certaines plateformes de publication en ligne ont choisi cette solution, l’exemple phare étant Medium et son éditeur light19 : les options de structuration sémantique et de mise en forme sont réduites au minimum, limitant les effets négatifs du WYSIWYG, mais rendant floues certaines options – le changement de taille du texte correspond en fait à un changement du niveau de titre.
Il faut dépasser l’approche WYSIWYG, successeur direct et maladroit des traitements de texte, il faut ainsi se dégager d’une uniformisation des pratiques et d’une complexité des systèmes pour envisager un autre fonctionnement pour l’écriture et l’édition numérique.
3. La possibilité d’une norme via des langages sémantiques simples
En proposant une issue simple, en terme d’usage, à l’écriture numérique, les traitements de texte et les modes WYSIWYG masquent d’autres solutions possibles pour l’écriture numérique, des solutions intégrant une véritable structuration sémantique visible par l’utilisateur. Nous nous devons d’aborder des systèmes plus complexes que les points précédemment traités pour comprendre quelle nouvelle approche permettrait d’atteindre, pour l’écriture, un niveau égal au HTML.
3.1. Un processus plutôt qu’un format
Les traitements de texte autant que les interfaces WYSIWYG simplifient la création et l’édition de documents numériques. Ce que nous n’avons pas encore mentionné c’est l’existence d’autres systèmes que des logiciels comme Word, cependant plus difficiles à appréhender et à utiliser. LaTeX fait partie de ces systèmes. Créé par Leslie Lamport en 1983 à partir de TeX de Donald Knuth, lui-même conçu en 1977, LaTeX est un langage sémantique et un procédé de génération de PDF et d’HTML, principalement développé pour l’impression de documents comme des articles et des livres. Sa syntaxe est riche et standardisée, mais compliquée à lire et à utiliser. Souvent manié avec un terminal en ligne de commande, LaTeX peut aussi être écrit avec des éditeurs graphiques. Rebutant pour des non-techniciens – que ce soit des techniciens de l’informatique ou de l’édition comme des chercheurs en sciences ou des éditeurs scientifiques –, le succès de LaTeX est autant durable que limité à un cercle de connaisseurs, trente quatre ans après sa création sa communauté est toujours aussi active20. Dans l’histoire de l’informatique, de la bureautique et de la publication assistée par ordinateur, les traitements de texte ont très vite remplacé des systèmes comme LaTeX, la raison principale étant l’apparente facilité d’utilisation des traitements de texte21.
Alors pourquoi aborder LaTeX ici ? LaTeX pose la question du processus22 : plutôt que de concevoir une solution complète fermée – comme un traitement de texte –, ou de masquer les options sémantiques en mettant en avant les aspects graphiques – comme une interface WYSIWYG –, LaTeX distingue les étapes d’inscription, de structuration et de production, ainsi que la structure et son rendu. Dans un premier temps chaque information est qualifiée par l’utilisation de balises, il s’agit de l’étape d’inscription et de structuration – en tant que tel un fichier TeX est aussi riche qu’un fichier HTML, et donc compliqué à lire. Dans un second temps un fichier PDF est généré à partir du fichier TeX, et de plusieurs paramètres propres à LaTeX – comme une feuille de style ou l’application de normes typographiques –, il s’agit de l’étape de production, c’est en ce sens que l’on peut parler d’une chaîne de publication. Les deux défauts principaux de LaTeX sont sa complexité d’usage et le manque de lisibilité du format brut de TeX : la génération d’un PDF depuis un fichier .tex peut provoquer des erreurs qu’il faut identifier et résoudre – cela fait partie de LaTeX, pourrait-on dire –, la modification de la feuille de style est délicate, et les nombreuses balises utilisées pour la structuration sémantique rendent un fichier TeX presque illisible.
LaTeX est un procédé d’écriture numérique très intéressant, sur son principe même, dont nous devons nous inspirer dans la recherche d’une solution d’écriture numérique comportant une puissance similaire au standard HTML.
3.2. Markdown
Entre d’un côté LaTeX – dont l’usage nécessite des connaissances techniques – et de l’autre côté une interface WYSIWYG faite de boutons et de menus, un langage sémantique simple – ou Lightweight markup language23 – présente l’avantage de respecter une logique sémantique, d’être lisible par les humains et pérenne grâce à sa simplicité syntaxique. Markdown est emblématique de ce concept de langage de balisage léger. Plus qu’un standard, Markdown ouvre la possibilité d’une norme dans l’action de l’écriture numérique.
D’une certaine façon Markdown est la rencontre de LaTeX et du Web : créé en 2004 par John Gruber, Markdown est un format libre et pivot entre le texte pur et le langage HTML.
Plutôt que de rédiger du texte non structuré, ou à l’inverse de devoir connaître une trop importante somme de balises HTML, Markdown traduit simplement une intention sémantique via une syntaxe simple compréhensible par des humains.
Cette syntaxe peut ensuite être transformée en standard lisible par des machines et des programmes : du code HTML interprété par des navigateurs web, des dispositifs de lecture numérique, mais aussi des synthèses vocales ou des plages braille.
Apprendre Markown ne demande que quelques minutes24, le gain en temps et en effort est donc bien supérieur à l’apprentissage d’un traitement de texte classique.
La syntaxe sémantique repose sur une poignée d’indications textuelles : * ou _ entourant un mot signale une emphase (comme l’italique), ** un passage en gras, # un niveau de titre 1, ## un niveau de titre 2, [^1] une note, etc.
Même si nous nous répétons ici, un fichier Markdown est donc un fichier au format texte brut qui sera interprété ou transformé.
L’édition d’un fichier Markdown peut se faire à partir d’un éditeur de texte, directement à partir de la syntaxe indiquée ci-dessus, ou avec des outils qui affichent graphiquement la valeur de la sémantique.
Markdown est un standard de fait25, en tant que tel il ouvre la possibilité pour des applications d’utiliser Markdown : coloration syntaxique dans des logiciels d’édition comme citée ci-dessus permettant une rédaction plus aisée ; interprétation du format dans des éditeurs en ligne – intégrés à des CMS ou des plateformes par exemple26 ; conversion du format en HTML, en PDF ou dans un format lisible par un traitement de texte via des outils dédiés27. Plusieurs usages de Markdown sont alors possibles, depuis l’édition dans un éditeur de texte et la transformation en HTML avec un outil en ligne de commande, jusqu’à l’utilisation d’un logiciel dédié interprétant le format et proposant des exports automatisés avec des feuilles de style modifiables28. À partir d’un standard technique, des applications technologiques émergent, ainsi que des usages d’écriture numérique.
 Figure 4 : texte au format Markdown et correspondance graphique
Figure 4 : texte au format Markdown et correspondance graphique
3.3. La naissance d’une norme ?
Markdown permet de transposer le paradigme de LaTeX en trouvant des applications pour un public bien plus large – sans connaissance technique préalable. L’utilisation de ce langage de balisage léger assure à un document une vraie structure sémantique, tout en le rendant pérenne, interopérable, et lisible aujourd’hui et dans dix ou vingt ans par une machine ou un humain – qui pourrait aujourd’hui prétendre qu’un fichier au format .doc sera encore lisible dans vingt ans ? Markdown transforme la puissance et la complexité de LaTeX en un processus accessible au plus grand nombre. Markdown supprime également toute dépendance à un logiciel – comme c’est le cas avec un traitement de texte, aussi ouvert ou libre qu’il soit – puisque le fichier Markdown n’est qu’un fichier en texte brut29. Résilient, Markdown est un standard si simple qu’il peut lui-même survivre à certaines de ses applications.
En apparence un élément peut freiner l’essor de Markdown : la granularité. En effet Markdown a été pensé pour créer des documents à un seul niveau – comme une page ou un article – plus que des documents à plusieurs niveaux comme des livres. Si LaTeX est un système complet – à la fois langage syntaxique et processeur générant différents formats –, conçu pour gérer autant le niveau article que le niveau livre, Markdown permet quand à lui de concevoir différents processus. Plus qu’un frein c’est donc une opportunité, une ouverture. Les applications basées sur Markdown peuvent ainsi être autant : un traitement de texte3031 ; une chaîne de publication pour livre imprimé et numérique32 ; un éditeur de contenus pour site web33 ; ou encore un générateur de site web34.
Par le biais d’un langage de balisage léger, compréhensible par des humains, standardisé, pérenne, interopérable, simple, nous sommes en mesure d’envisager une norme pour l’écriture numérique. Le processus d’écriture sur Markdown, ouvert mais néanmoins délimité, pourrait se définir en plusieurs phases :
- inscription et structuration sémantique : écriture du fichier Markdown en texte brut, la structuration sémantique est réalisée avec la syntaxe de Markdown ;
- interprétation ou transformation du format : par exemple transformation de Markdown en HTML5 ;
- organisation du ou des fichiers Markdown dans le cas de documents complexes – il y a donc ici une dimension méta pour l’organisation.
Pourquoi aborder le concept de norme ? Le format Markdown n’est pas en lui-même une norme, c’est un standard appliqué à la structuration sémantique de contenus. Ce format technique permet le développement de technologies. L’utilisation de Markdown comme format central ou pivot dans un processus défini d’écriture numérique constitue une norme. La notion de norme ne doit pas être entendue, ici, au sens d’un aplanissement, d’un comportement à adopter, mais plutôt dans la perspective d’une universalité. En étant un langage syntaxique facile d’utilisation – pour des humains ou des machines –, Markdown donne au processus d’écriture numérique une véritable existence, une application possible qui n’est pas réservée qu’à une élite technique. Enfin, c’est à partir de ce processus normalisé que d’autres processus peuvent être développés, que l’écriture – numérique ou non – peut demeurer pluriel et riche.
Conclusion
Un langage de balisage léger est un moyen, et non une fin en soi. Utiliser Markdown c’est garantir une certaine vitalité intellectuelle pour nos pratiques d’écriture, car il est très simple de passer à un autre langage de balisage. AsciiDoc permet par exemple de rédiger très facilement de la documentation avec une syntaxe plus riche que Markdown, mais tout aussi compréhensible. Associé à Asciidoctor35 – un processeur interprétant AsciiDoc et permettant de générer différents formats comme du HTML, du PDF ou du .doc –, AsciiDoc repose sur le même type de processus normalisé qu’exposé ci-dessus. Nous aurions pu tout aussi bien intituler cet article “AsciiDoc comme condition d’une norme de l’écriture numérique”.
Markdown est un standard. Markdown et d’autres langages de balisage léger ouvre la perspective d’une norme d’écriture numérique. Markdown (re)pose le langage de balisage comme point de départ, loin des logiciels boîtes noires dont le fonctionnement est inintelligible et générateur de confusions. Markdown place le système au centre du processus d’écriture et de lecture numérique, ce standard nous donne la possibilité de penser un procédé cohérent36, en adéquation avec les objectifs des utilisateurs qui y recourent. Sans déléguer leur faculté de compréhension sémantique.
Bibliographie
R. T. Pédauque, Le document à la lumière du numérique, Caen, C&F éditions, 2006.
P. Benoît, « Paul Otlet. Le bibliographe rêveur », Revue de la BNF, Paris, BNF, 2012/3 (numéro 42) : http://www.cairn.info/revue-de-la-bibliotheque-nationale-de-france-2012-3-page-5.htm (page visitée le 8 septembre 2017).
B. Bachimont, S. Crozat, « Instrumentation numerique des documents : pour une separation fonds/forme », Revue I3 - Information Interaction Intelligence, Cépaduès, 2004 : https://hal.archives-ouvertes.fr/sic_00001017/document (page visitée le 8 septembre 2017).
E. Schrijver, Culture hacker et peur du WYSIWYG, Back Office, Paris, B42 et Fork Éditions, 2016, numéro 1.
J. Panoz, WYSIWYG Not — Starter Kit InDesign EPUB, 2 avril 2015 : http://jiminy.chapalpanoz.com/wysiwyg-not-starter-kit-indesign-epub/ (page visitée le 8 septembre 2017).
R. Têtue, What you see is what you… ?, 26 juillet 2014 : http://romy.tetue.net/wysiwyg-wysiwym-wysiwyc (page visitée le 8 septembre 2017).
E. Guichard. « L’écriture scientifique : grandeur et misère des technologies de l’internet », Sens Public, Paris, 2008 (numéro 7-8), p. 53-79 : https://hal-ens.archives-ouvertes.fr/file/index/docid/347616/filename/CIPH2006.Guichard.pdf (page visitée le 8 septembre 2017).
A. Fauchié, LaTeX et Jekyll : deux workflows de publication, 26 avril 2014 : https://www.quaternum.net/2014/04/26/latex-et-jekyll/ (page visitée le 8 septembre 2017).
N. Guilhou, Brûlons les « traitements de texte » embarqués, 7 novembre 2011 : https://web.archive.org/web/20160408080814/http://nicolas-guilhou.com:80/news/2012/11/07/Brulons_les-traitements_de_texte-embarques (page visitée le 8 septembre 2017).
E. Williams, Writing in Medium, 15 novembre 2002 : https://medium.com/@ev/writing-in-medium-df8eac9f4a5e (page visitée le 8 septembre 2017).
iA, Multichannel Text Processing, 10 juin 2016 : https://ia.net/topics/multichannel-text-processing/ (page visitée le 8 septembre 2017).
A. Fauchié, « Publier des livres avec un générateur de site statique », Jamstatic, 23 janvier 2017 : https://jamstatic.fr/2017/01/23/produire-des-livres-avec-le-statique/ (page visitée le 8 septembre 2017).
F. Taillandier, La mouvance statique, 8 mars 2016 : https://frank.taillandier.me/2016/03/08/les-gestionnaires-de-contenu-statique/ (page visitée le 8 septembre 2017).
-
What You See Is What You Get, ou ce que vous voyez est ce que vous obtenez en français. ↩︎
-
L’acronyme PDF signifie “Portable Document Format”. ↩︎
-
« Roger [T. Pédauque] nous invite à conclure que l’affaire du document n’est ni sa matière, ni sa forme, mais son usage. » in R. T. Pédauque, Le document à la lumière du numérique, Caen, C&F éditions, 2006. ↩︎
-
P. Benoît, « Paul Otlet. Le bibliographe rêveur », Revue de la BNF, Paris, BNF, 2012/3 (numéro 42), p. 5-12 : http://www.cairn.info/revue-de-la-bibliotheque-nationale-de-france-2012-3-page-5.htm (page visitée le 8 septembre 2017). ↩︎
-
Chapitre « Pédauque 1. Document : forme, signe et médium, les re-formulations du numérique » in Ibid. ↩︎
-
« HTML » : https://en.wikipedia.org/wiki/HTML (page visitée le 8 septembre 2017). ↩︎
-
« HTML5 (HyperText Markup Language 5) est la dernière révision majeure du HTML (format de données conçu pour représenter les pages web). » in « HTML5 » : https://fr.wikipedia.org/wiki/HTML5 (page visitée le 8 septembre 2017). ↩︎
-
Les navigateurs sont encore en mesure d’interpréter et d’afficher les premières versions d’HTML, vingt-cinq ans plus tard. On ne peut pas en dire autant de beaucoup de formats. ↩︎
-
« […] un utilisateur de documents électroniques n’est confronté qu’à des documents mis en forme. » in B. Bachimont, S. Crozat, « Instrumentation numerique des documents : pour une separation fonds/forme », Revue I3 - Information Interaction Intelligence, Cépaduès, 2004 : https://hal.archives-ouvertes.fr/sic_00001017/document (page visitée le 8 septembre 2017). ↩︎
-
Flipboard ou Wallabag sont deux exemples d’applications qui permettent la lecture de pages ou articles web indépendamment des sites originels. ↩︎
-
Jeremy Thomas a créé le site web « Web Design in 4 minutes » pour montrer la distinction entre le fond et la forme. Voir « Web Design in 4 minutes » : http://jgthms.com/web-design-in-4-minutes/ (page visitée le 8 septembre 2017). ↩︎
-
« What Comes Next Is The Future », un documentaire de Matt Griffin. Voir « What Comes Next Is The Future » : http://www.futureisnext.com/ (page visitée le 8 septembre 2017). ↩︎
-
Publication assistée par ordinateur. ↩︎
-
« Alors qu’une des modalités essentielles des documents traditionnels matérialisés sur un support papier est que le contenu inscrit sur ce support est directement proposé à la lecture, l’accès à l’information sur le support numérique n’est jamais direct mais nécessairement médié par le calcul. Elle passe au minimum par le décodage d’une représentation sous forme binaire de l’information pour en proposer une présentation sous une forme sémiotique lisible. Le document numérique, si l’on peut encore parler de document, est donc toujours une reconstruction dynamique. » in B. Bachimont, S. Crozat, « Instrumentation numerique des documents : pour une separation fonds/forme », Revue I3 - Information Interaction Intelligence, Cépaduès, 2004 : https://hal.archives-ouvertes.fr/sic_00001017/document (page visitée le 8 septembre 2017). ↩︎
-
E. Schrijver, Culture hacker et peur du WYSIWYG, Back Office, Paris, B42 et Fork Éditions, 2016, numéro 1. ↩︎
-
J. Panoz, WYSIWYG Not — Starter Kit InDesign EPUB, 2 avril 2015 : http://jiminy.chapalpanoz.com/wysiwyg-not-starter-kit-indesign-epub/ (page visitée le 8 septembre 2017). ↩︎
-
N. Guilhou, Brûlons les « traitements de texte » embarqués, 7 novembre 2011 : https://web.archive.org/web/20160408080814/http://nicolas-guilhou.com:80/news/2012/11/07/Brulons_les-traitements_de_texte-embarques (page visitée le 8 septembre 2017). ↩︎
-
R. Têtue, What you see is what you… ?, 26 juillet 2014 : http://romy.tetue.net/wysiwyg-wysiwym-wysiwyc (page visitée le 8 septembre 2017). ↩︎
-
E. Williams, Writing in Medium, 15 novembre 2002 : https://medium.com/@ev/writing-in-medium-df8eac9f4a5e (page visitée le 8 septembre 2017). ↩︎
-
L’activité récente de la communauté francophone de LaTeX est visible par exemple avec deux journées organisées en septembre 2017, « Journées LATEX. Édition et typographie numériques, épistémologie ». Programme disponible à l’adresse : http://barthes.enssib.fr/LaTeX-2017/ (page visitée le 8 septembre 2017). ↩︎
-
E. Guichard. « L’écriture scientifique : grandeur et misère des technologies de l’internet », Sens Public, Paris, 2008 (numéro 7-8), p. 53-79 : https://hal-ens.archives-ouvertes.fr/file/index/docid/347616/filename/CIPH2006.Guichard.pdf (page visitée le 8 septembre 2017). ↩︎
-
A. Fauchié, LaTeX et Jekyll : deux workflows de publication, 26 avril 2014 : https://www.quaternum.net/2014/04/26/latex-et-jekyll/ (page visitée le 8 septembre 2017). ↩︎
-
« Lightweight markup language » : https://en.wikipedia.org/wiki/Lightweight_markup_language (page visitée le 8 septembre 2017). ↩︎
-
« Markdown Tutorial » : http://commonmark.org/help/tutorial/ (page visitée le 8 septembre 2017). ↩︎
-
En vérité Markdown n’est pas un standard au sens où il existe plusieurs versions avancées de ce langage de balisage léger, il s’agit de variantes implémentées de façons diverses. L’initiative CommonMark tente depuis plusieurs années de proposer une spécification précise sur laquelle tous le monde pourrait s’accorder. Voir « CommonMark, A strongly defined, highly compatible specification of Markdown » : https://commonmark.org/ (page visitée le 25 octobre 2018). ↩︎
-
Nombreuses sont les plateformes dont l’éditeur de texte intégré repose sur Markdown, nous pouvons citer les plateformes d’hébergement de code GitHub et GitLab, le site de cartographie collaboratif et libre OpenStreetMap, le réseau social décentralisé Diaspora, la plateforme de publication Ghost, de nombreux types de forums, etc. ↩︎
-
L’un des plus populaires est Pandoc, utilisable en ligne de commande ce qui n’en fait pas non plus un outil grand public. ↩︎
-
Le logiciel/application iA Writer est représentatif de ce type d’usage. Voir « About iA Writer » : https://ia.net/writer/ (page visitée le 8 septembre 2017). ↩︎
-
iA, Multichannel Text Processing, 10 juin 2016 : https://ia.net/topics/multichannel-text-processing/ (page visitée le 8 septembre 2017). ↩︎
-
iA développe le logiciel/application iA Writer, véritable traitement de texte basé sur Markdown, comportant notamment une fonction d’intégration et d’organisation de plusieurs fichiers et documents. ↩︎
-
Cet article a d’ailleurs d’abord été écrit en Markdown, avant d’être transformé dans un format intégré à la chaîne d’édition de la revue Réel - Virtuel. ↩︎
-
A. Fauchié, « Publier des livres avec un générateur de site statique », Jamstatic, 23 janvier 2017 : https://jamstatic.fr/2017/01/23/produire-des-livres-avec-le-statique/ (page visitée le 8 septembre 2017). ↩︎
-
Le CMS Roadiz intègre par défaut une éditeur de contenus utilisant Markdown. Voir « Write in Markdown » : http://docs.roadiz.io/en/latest/user/write-in-markdown/index.html (page visitée le 8 septembre 2017). ↩︎
-
F. Taillandier, La mouvance statique, 8 mars 2016 : https://frank.taillandier.me/2016/03/08/les-gestionnaires-de-contenu-statique/ (page visitée le 8 septembre 2017). ↩︎
-
« A fast text processor & publishing toolchain for converting AsciiDoc to HTML5, DocBook & more. » in https://asciidoctor.org/ (page visitée le 8 septembre 2017). ↩︎
-
Nous utilisons ici le concept de cohérence au sens où Gilbert Simondon peut l’envisager comme élément de perfection pour les objets techniques. Voir G. Simondon, Du mode d’existence des objets techniques, Paris, Aubier, 2012, pp. 58-59. ↩︎